From Data Lakes to Delta Lakes – Part IV: The Lakehouse Revolution
🚀 Most AI initiatives don’t fail because the model is weak.
They fail because the organisation was never AI-ready.
AI doesn’t fix broken data, poor governance, or unclear decision-making.
It amplifies them — at machine speed.
Before investing in larger models, agents, or copilots, organisations must answer a harder question:
Is our data foundation actually capable of supporting AI in production?
🧩 Context & Problem Statement
Across industries, organisations are rushing to deploy GenAI, RAG systems, and agentic workflows. Yet the majority of these initiatives stall after the demo stage.
The root causes are remarkably consistent:
Data quality is inconsistent or unknown
Governance is fragmented or manual
Operational and strategic data are mixed without boundaries
AI produces insights, but nothing in the organisation is designed to act on them
There are no feedback loops to improve outcomes over time
This is not a technology failure.
It is a data and decision architecture failure.
Concept Overviewe
AI-ready data means data that is:
Trusted – validated, reliable, and well-defined
Controlled – governed by policy, ownership, and access rules
Contextual – enriched with semantics, metadata, and relationships
Actionable – designed to support decisions, not just reports
Self-improving – continuously refined through feedback
Without these properties, AI systems become unpredictable, unsafe, and unscalable.
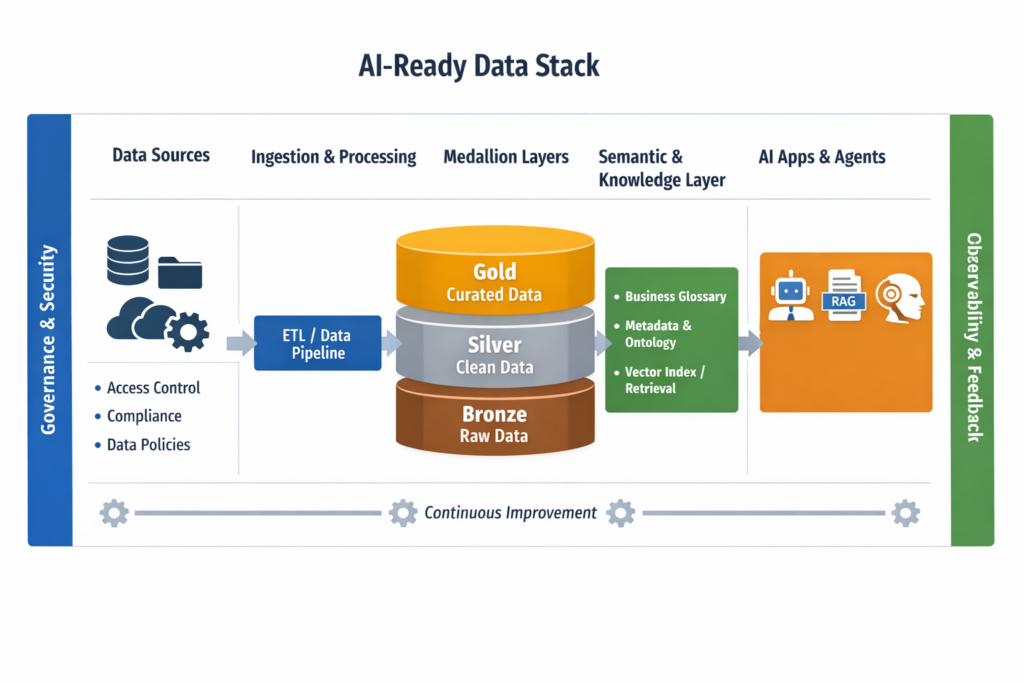
⚙ How It Works
1️⃣ Separate Operational and Strategic Data
Operational data: events, transactions, logs, real-time signals
Strategic data: curated, reconciled, decision-grade models
AI systems often require both — but confusing them destroys trust.
2️⃣ Use a Layered Data Pattern
- Bronze – raw, immutable, traceable
Silver – cleaned, validated, standardised
Gold – business-ready, optimised for decisions
3️⃣ Add Governance and Semantics
AI must understand:
what the data means
who owns it
who can access it
how it can be used
This is enabled through catalogs, glossaries, lineage, and policy enforcement.
4️⃣ Introduce Feedback Loops
Capture:
user corrections
decision outcomes
hallucinations and retrieval failures
data and behaviour drift
AI readiness is not static — it is continuously earned.
# Simple example: data quality gate before AI consumption
def validate_records(records):
errors = []
for i, r in enumerate(records):
if not r.get("entity_id"):
errors.append((i, "Missing entity_id"))
if r.get("confidence", 0) < 0.8:
errors.append((i, "Low confidence score"))
return errors
records = [
{"entity_id": "A123", "confidence": 0.92},
{"entity_id": None, "confidence": 0.65},
]
issues = validate_records(records)
if issues:
raise ValueError(f"Validation failed: {issues}")
| Feature | Option A: AI on Raw Data | Option B: AI-Ready Foundation | Recommendation |
|---|---|---|---|
| Data quality | Unknown / inconsistent | Validated with gates | Option B |
| Governance | Manual / ad-hoc | Policy-driven | Option B |
| Context | Minimal | Semantic + metadata layer | Option B |
| Production reliability | Fragile | Stable and auditable | Option B |
❌ Pitfalls / Anti-Patterns
✅ Best Practices
Define data contracts for critical datasets
Enforce quality gates at every layer
Separate decision data from operational noise
Implement policy-based access for AI retrieval
Measure outcomes, not just model accuracy
📌 Key Takeaways
AI failures are usually data and governance failures
AI-ready data is layered, governed, contextual, and actionable
Decision architecture matters as much as model choice
Feedback loops turn AI from a tool into a system
